
鐵人賽終於進入倒數階段,我們也已經介紹完科技公司在機器學習專案中每個步驟的實作方式,接下來,該來正式建立一個完整的 ml 專案吧!
我們會在三天的內容中,規劃一個 ml 專案的步驟以及他們需要的工具,不過不代表我介紹的這些工具是最好的,世界上還是有相當多的競品,要根據自己的需求選擇。
以下是每個步驟以及選擇的工具:
Step 1. 搜集和準備資料
Step 2. 建立模型
Step 3. 將模型整合到應用程式中
Step 4. 監控模型表現
我們曾經在前面的內容,介紹過 Metaflow 能夠幫助我們建立資料處理和執行模型的 pipelines,也可以很方便地在 local 和 cloud 上面執行切換,並且可以使用 card 和 Metaflow UI 以視覺化整個工作流程(workflow)的過程和資料內容。
有關 Metaflow 的介紹可以參考 Metaflow 介紹 Part 1、Part 2 和 Part 3。
不過,Metaflow 主要專注於數據科學的工作流程,無法支持更複雜的 ETL 過程。另外,Metaflow 的調度功能相對簡單,主要依賴外部調度器(如 AWS Step Functions),他們缺乏內建的調度機制,無法基於時間或事件而觸發工作流程。再者,雖然 Metaflow 提供了基本的視覺化功能,但是在大規模的 production 環境中,監控和報告功能可能不夠強大。
因此,如果是單純想要建立資料處理的 pipeline,那 Metaflow 就已經足夠。不過,如果想要編排更複雜的 workflow,例如涉及多個系統的協調、需要定期執行任務,如資料 ETL、模型重新訓練等等,也想要有更強大的錯誤處理和任務重試機制的話,那也可以考慮使用 Airflow 或 Dagster。
那我們接下來就來簡單介紹這兩個工具吧!
Apache Airflow 是 Airbnb 開發並變成開源的工具,是一個工作流程管理系統,用於編排、調度和監控工作流,可以被用來建構 ETL 以及定期處理資料,主要關注任務的順序和依賴關係。
基於 DAG(Directed Acyclic Graph)(有向無環圖) 來定義工作流。「有向」意即工作流的是有方向的,會從上游開始往下執行每個工作,「無環」是指當任務依序完成後,不會回頭執行前幾個步驟。Airflow 用 DAG 描述不同任務之間的關係,以及定義執行順序。
動態生成任務:Airflow 允許根據運行時的條件,或是外部資料的狀況而動態地建立任務。舉例來說,假設我們想要每天定期處理一個資料庫的所有表格,但是這個表格數量是會每日變動的。此時,我們不需要手動修改 DAG,而是可以直接讓 Airflow 每天自動抓取這個資料庫中的所有表格數量,並為為每個表格生成一個任務。這個功能提供非常大的靈活性,使得工作流可以適應變化的數據,不需要人為手動修改。
功能豐富的 UI 介面,可用於監控和管理工作流。Airflow 提供各式各樣的 UI,如下圖所示,讓使用者得以看到 DAG 的結構,監控任務執行狀態,也可以查看日誌,或是手動觸發或暫停任務,提高工作流的可管理性和可觀察性。
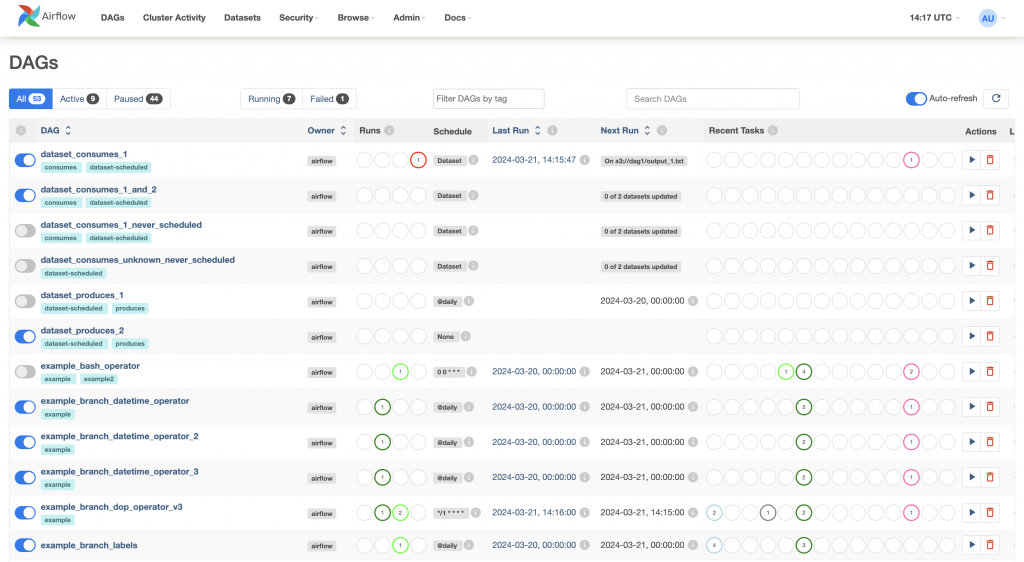
圖片來源:https://airflow.apache.org/docs/apache-airflow/stable/ui.html
接下來是一個簡單的 Airflow DAG 示範。
from datetime import datetime
from airflow import DAG
from airflow.decorators import task
from airflow.operators.bash import BashOperator
# A DAG represents a workflow, a collection of tasks
## 這個 DAG 名稱為 demo,執行時間從 2024 年 1 月 1 號開始,每天執行一次
with DAG(dag_id="demo", start_date=datetime(2024, 1, 1), schedule="0 0 * * *") as dag:
# Tasks are represented as operators
## 第一個任務:執行一個 bash script
hello = BashOperator(task_id="hello", bash_command="echo hello")
## 第二的任務:執行 Python function
@task()
def airflow():
print("airflow")
# Set dependencies between tasks
## 用 >> 描述任務之間的執行順序
hello >> airflow()
程式碼來源:https://airflow.apache.org/docs/apache-airflow/2.10.0/index.html
Dagster 的設計理念跟 Airflow 有所不同,他們鼓勵我們思考數據如何流動和轉換,而不只是單純的任務序列,這讓我們在思考如何管理複雜的數據依賴關係時會變得更加直觀。
Dagster 的核心概念是「數據資產(data asset)」而非僅僅是任務,強調數據生命週期的整體管理,從 local 開發、測試,一直到部署到 production 和監控,讓追蹤 data lineage 變得更加容易,使用者可以清楚地看到哪些程式碼產生了哪些數據。
一個 data asset 指的是一個儲存在永久儲存體中的物件,例如表格、檔案或機器學習模型。
Dagster 透過 asset definition,提供一種宣告式資料管理的方式,讓程式碼成為資料資產存在方式和計算方法的唯一來源,描述應該存在的 asset,以及如何產生和更新該 asset。Asset definition 包含 AssetKey、上游 AssetKey,以及負責計算 asset 內容的 Python 函數。這個內容描述了一個 asset 是從哪一個上游、經過哪一個 Python 函數產生而成的。
更白話一點的解釋就是,當我們每次在寫 Python 函數時,就是在撰寫 asset definition,因為這個函數會包含使用到的上游 asset、處理的方式,以及最後會產出的內容。
另外,Dagster 還有一個概念稱為 materializations,materializing an asset 指的是執行一個函數,並將結果儲存到永久儲存體。可以從 Dagster UI 或透過呼叫 Python API 來啟動 materializations。
下圖示範如何在 Dagster UI 執行 materializations。
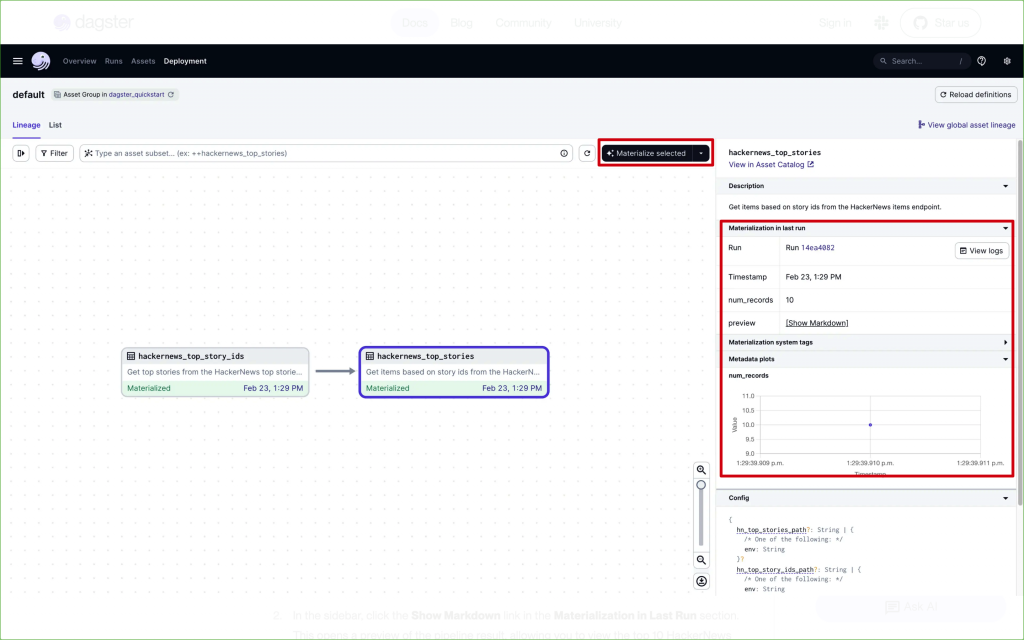
圖片來源:[2]
如果點擊上圖中右側的 Show Markdown,則會顯示這次儲存的 data asset 內容,如下圖所示:
圖片來源:[2]
接著,讓我們用 Python 程式碼示範如何宣告一個 data asset。
以下是 topstories 這個 data asset 的定義,他的上游是來自於另一個稱為 topstory_ids 的 data asset。
@asset(deps=[topstory_ids]) ## 上游 asset
def topstories(context: AssetExecutionContext) -> MaterializeResult: ## 定義輸入和輸出的格式
with open("data/topstory_ids.json", "r") as f:
topstory_ids = json.load(f)
results = []
for item_id in topstory_ids:
item = requests.get(
f"https://hacker-news.firebaseio.com/v0/item/{item_id}.json"
).json()
results.append(item)
if len(results) % 20 == 0:
print(f"Got {len(results)} items so far.")
df = pd.DataFrame(results)
df.to_csv("data/topstories.csv")
return MaterializeResult(
metadata={
"num_records": len(df), # Metadata can be any key-value pair
"preview": MetadataValue.md(df.head().to_markdown()),
# The `MetadataValue` class has useful static methods to build Metadata
}
)
程式碼來源:[2]
在 Dagster UI 上,會以下圖的方式呈現 data asset 的關係,這樣大家應該可以很清楚地感受到 Dagster 和 Airflow 的差異,Dagster 是以「數據」本身來繪製 DAG,而非如 Airflow 是以任務。因此,我們可以更好地掌握每個數據是如何被產生的。
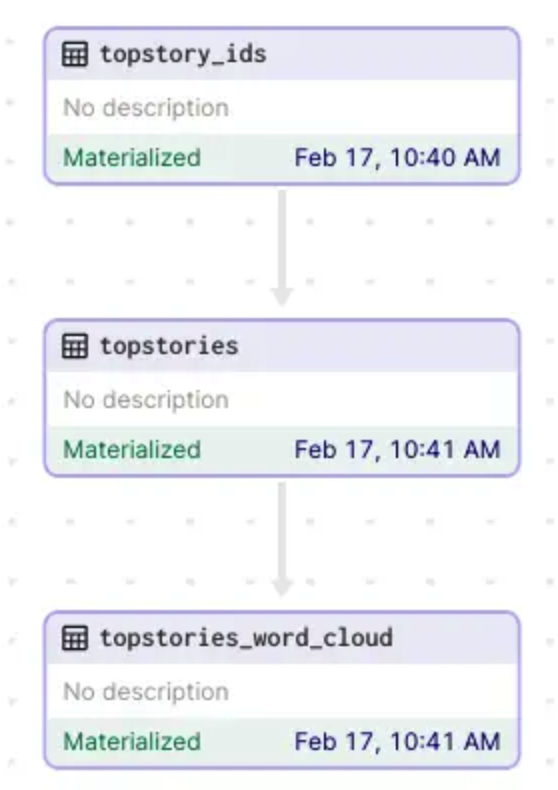
圖片來源:[2]
還可以看到每次 data asset 被 materialized 的內容。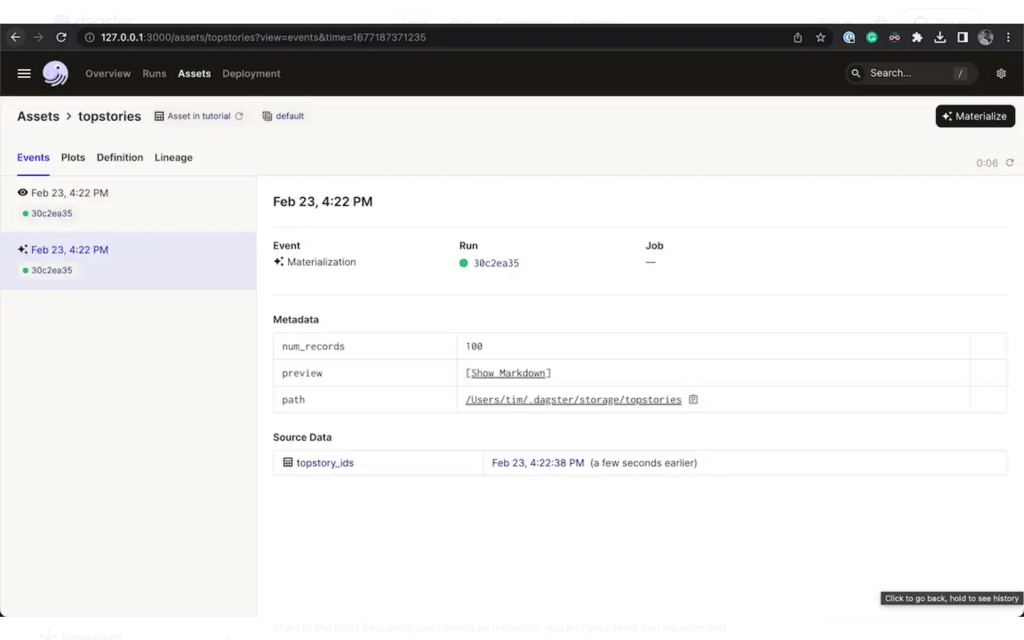
圖片來源:[2]
接下來我們來認識 Dagster 的其他特點。
最後,讓我們來比較一下 Airflow 和 Dagster 吧!
兩者都是開源項目,都使用 Python 作為主要語言,也都提供豐富的 UI 來監控和管理工作流。
不過,兩者的核心概念和功能還是略有差異。
如前面所介紹,Dagster 專注於 data asset 的概念,而非只是任務本身。而 Airflow 更專注於任務的執行,使用 DAG 來調度處理任務。
另外,Dagster 可以讓開發者方便地在 local 開發,進行快速迭代和測試,無需依賴外部環境。 Airflow 在local 測試相對較繁瑣,可能需要在 local 複製 production 環境。
再者,Dagster 可以支援手動執行,以及有條件的調度(如根據條件設定工作日和週末的不同 config)。而 Airflow 要求所有 DAG 都必須有一個時間表。
以上就是 Dagster 和 Airflow 的簡單介紹啦。雖然他們都是 data pipeline 的編排管理工具,但是可以很明顯地看到兩者關注的重點不同,也和 Metaflow 有很大的不同。
至於到底大家實際上要使用哪個呢?還是要根據自身需求,或是再多看看他們的官網範例評估之後,再挑選最適合的工具啦。
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
如果有任何問題想跟我聊聊,或是想看我分享的其他內容,也歡迎到我的 Instagram(@data.scientist.min) 逛逛!
我們明天見!
Reference:
[1] https://airflow.apache.org/docs/apache-airflow/2.10.0/index.html
[2] https://docs.dagster.io/tutorial/introduction
